上一篇文章介绍了利用协同过滤的方法计算用户之间的相似度,基于用户的协同过滤,从定义来说,可以简单描述为以下两步:
- 找到和目标用户兴趣相似的用户集合
- 找到目标用户没有对该物品有过行为,但和目标用户兴趣相似的用户集合喜欢的物品,推荐给目标用户
本文使用MovieLens的1M数据集,这里计算用户相似度只用到了数据ratings.data.
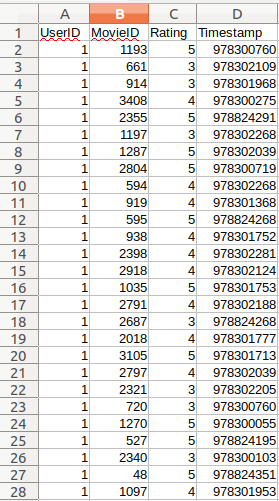 ratings.data中包含userid,以及user对观看过的movie的评分信息与时间
ratings.data中包含userid,以及user对观看过的movie的评分信息与时间为了方便处理,本文已经将user.data转换为user.csv,这份数据集可以点击这里下载
首先我们找出用户没有看过的电影
def get_candidates_items(csvpath, target_user_id):
frame = pd.read_csv(csvpath)
target_user_movies = set(frame[frame['UserID'] == target_user_id]['MovieID'])
other_user_movies = set(frame[frame['UserID'] != target_user_id]['MovieID'])
candidates_movies = list(target_user_movies ^ other_user_movies)
return top_n_users在上一篇文章中已经讲过了,可以参考:推荐系统之协同过滤计算用户相似度
def get_top_n_items(csvpath, top_n_users, candidates_movies, top_n):
frame = pd.read_csv(csvpath)
top_n_user_data = [frame[frame['UserID'] == k] for k, _ in top_n_users]
interest_list = []
for movie_id in candidates_movies:
tmp = []
for user_data in top_n_user_data:
if movie_id in user_data['MovieID'].values:
tmp.append(user_data[user_data['MovieID'] == movie_id]['Rating'].values[0] / 5)
else:
tmp.append(0)
interest = sum([top_n_users[i][1] * tmp[i] for i in range(len(top_n_users))])
interest_list.append((movie_id, interest))
interest_list = sorted(interest_list, key=lambda x: x[1], reverse=True)
return interest_list[:top_n]运行上面的程序,得到以下结果,可以看到推荐的电影以及预测的用户感兴趣程度.
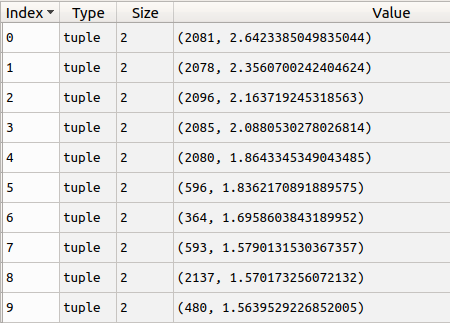 向user_id为1的用户推荐的10部电影
向user_id为1的用户推荐的10部电影在看推荐系统为用户推荐了什么电影之前,让我们先看一下user_id为1的用户的个人信息.用户的年龄与职业信息可以从这里下载:
字段说明可以从这里获得:
 user_id=1的个人信息
user_id=1的个人信息可以看出来,这个用户是一个年龄小于18岁的女孩,职业是:”K-12 student”(Age=1表示年龄小于18岁,Occupation=10表示职业为K-12 student)
电影名字以及分类信息可以从这里获得.和ratings.csv一样,我们也将movies.data转换成了csv格式.
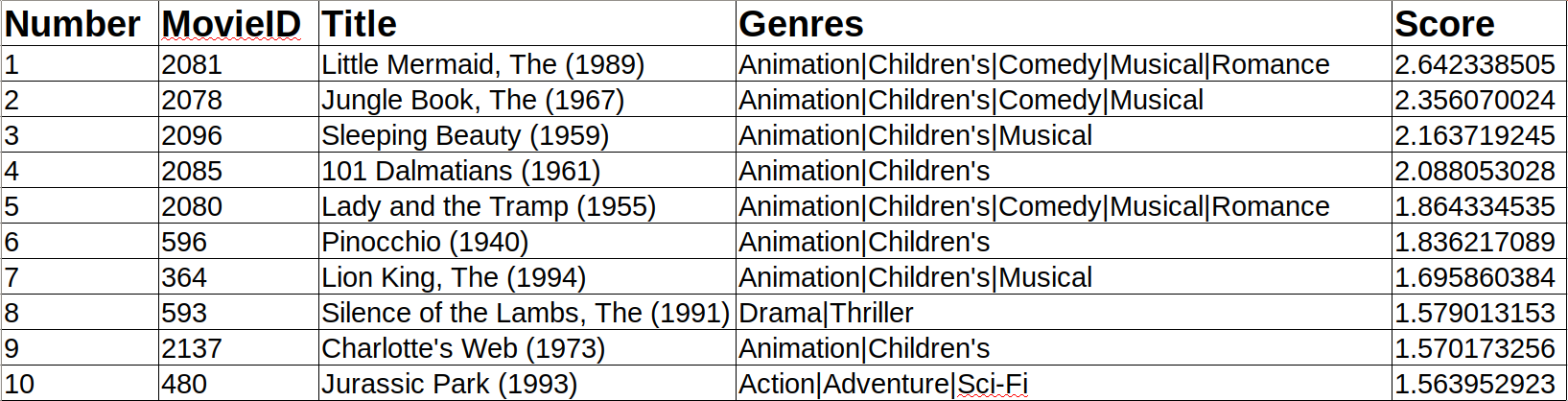 推荐系统向用户推荐的电影
推荐系统向用户推荐的电影我们的推荐系统给用户推荐的电影主题主要有:Animation|Children’s|Adventure|Comedy|Musical|Romance|Drama,可以看出这些应该是比较轻松,愉快,浪漫的电影.
因此,可以认为推荐系统推荐的电影与用户的信息,观影历史存在一定的相关性.
参考资料:

发表回复