机器在学习
语句相似度的计算,在文本对比,内容推荐,重复内容判断等方面有比较多的应用,本文介绍了一种基于LSTM的语句相似度计算方法。
本文基于Siamese网络,句子相似度计算方法论文:Siamese Recurrent Architectures for Learning Sentence Similarity
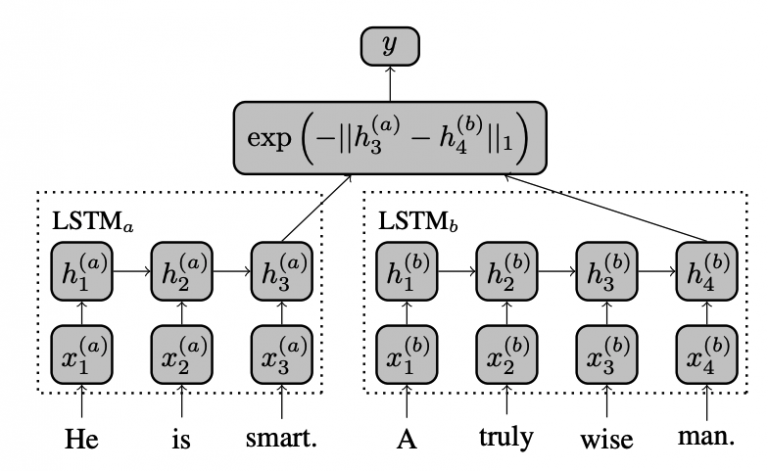
Siamese Network 是指⽹络中包含两个或以上完全相同的⼦⽹络,多应 ⽤于语句相似度计算、⼈脸匹配、签名鉴别等任务上:
以语句相似度计算为例,两边的⼦⽹络从 Embedding 层到 LSTM 层等 都是完全相同的,整个模型称作 MaLSTM(ManhaĴan LSTM)。
通过 LSTM 层的最后输出得到两句话的固定长度表⽰,再使⽤以下公式 计算两者的相似度,相似度在 0 ⾄ 1 之间。
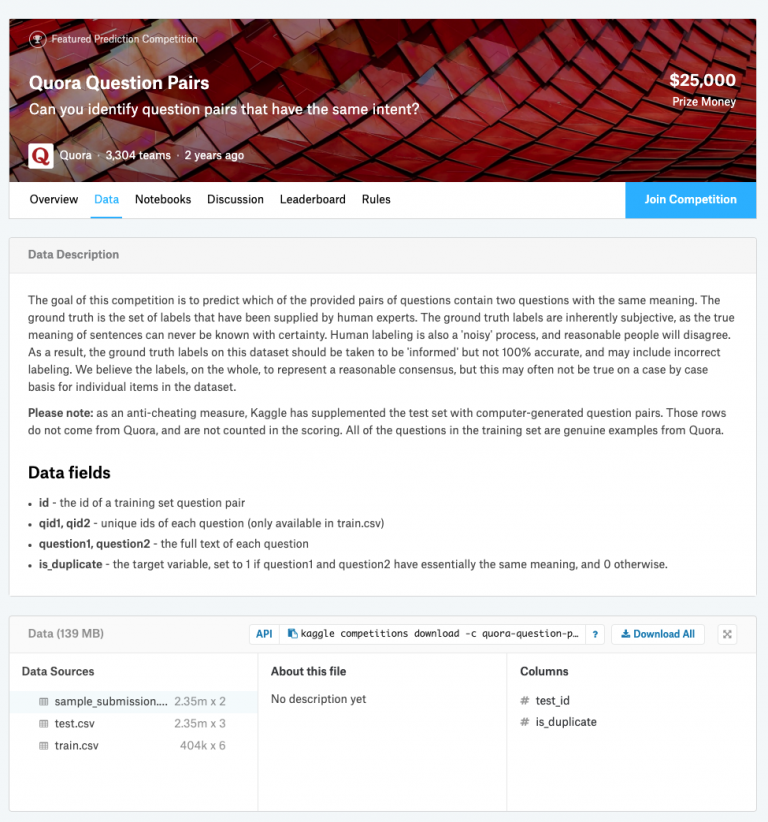
训练用的数据来自kaggle上quora的问题对数据:数据地址
其中,训练集与测试集分别有 404290 和 3563475 条数据。训练集包含以下所有字段,测试集不包含is_duplicate字段。
首先加载停用词,用正则表达式对文本进行一些预处理,将测试数据与训练数据合并后,得到所有单词的词汇列表,⽂本替换成整数序列表⽰,获得词向量映射矩阵,采用曼哈顿距离来计算两个句子的差异。
下载的数据里,测试集由于缺少is_duplicate字段,因此它只参与了词汇向量映射矩阵的构建。
将包含is_duplicate字段的训练数据分割为训练集和验证集,参与模型训练迭代过程。
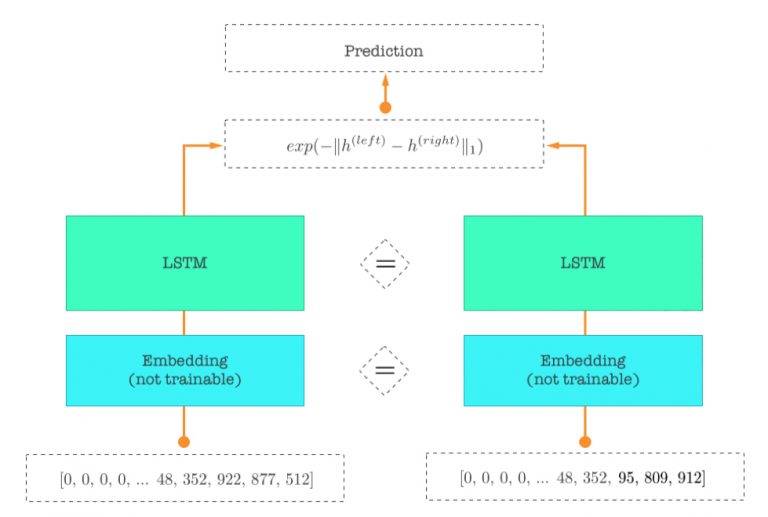
基于Keras定义LSTM网络,并进行训练,网络结构采用两个句子作为输入,对输入的句子进行预处理后,计算出句子相似度的概率。
下图是整个网络大致的过程,左右两个句子输入后,句子中的每个词对应一个数字,左右两句话分别映射成一个向量,各自经过一个LSTM网络抽取特征后,使用曼哈顿距离计算两边向量的差距,最终得出预测结果。
具体代码,可以参考:MaLSTM on Kaggle’s Quora Question Pairs
参考地址:
The End
已发布
分类
标签:
您的电子邮箱地址不会被公开。 必填项已用*标注
评论 *
显示名称
电子邮箱地址
网站地址
Δ
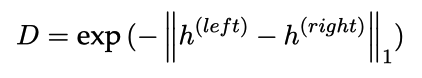

发表回复