机器在学习
上周参加了公司举办的“平安集团“数创杯”数据建模大赛”,这次比赛吸引了平安集团的多家专业子公司的24支数据建模团队参加。
本次比赛的赛题是“某金融产品的购买行为预测”,根据用户的一些特征,预测用户是否会购买是否产生购买行为。
我和一名队友JLL组队参加了这次比赛,比赛主办方12月12日开放了比赛平台,发布了部分数据集供参赛选手进行试炼。我们拿到数据后 ,进行了一些分析,建模,但很遗憾,队友比赛的那天,有更加重要的事情。所以我只能独自一人到现场参加比赛。
现场比赛的时间非常短,从12月15日上午9:00开放正式比赛平台,到12月16日14:00结束比赛。中间只有短短的29个小时,期间经历了多次平台不稳定,系统崩溃,无法登陆,提交等问题。
相比其他队的4个人,现场我只有自己一个人,人力上来说,明显吃亏很多。因此,我只能采用比较快速,保守的策略。
比赛使用jupyter编辑器,数据不可导出到本地,必须使用平安集团的克里斯平台。
在数据的与处理上,对部分string类型的数据进行了one hot编码转换处理,其他结构化的数据直接拿来使用。之后使用GBDT,gbm,RF,LR等方法逐一测试,选择模型。
最后得到的结论是GBDT效果比较好,因此我确认了使用GBDT进行建模。比赛采用的评分标准是F1Score,GBDT输出的预测值是一个概率值,而真实值是一个0-1的二分类值,这里我使用了一个动态阈值的方法,来得到一个最优的分割点a,大于a的值置1,反之置0。
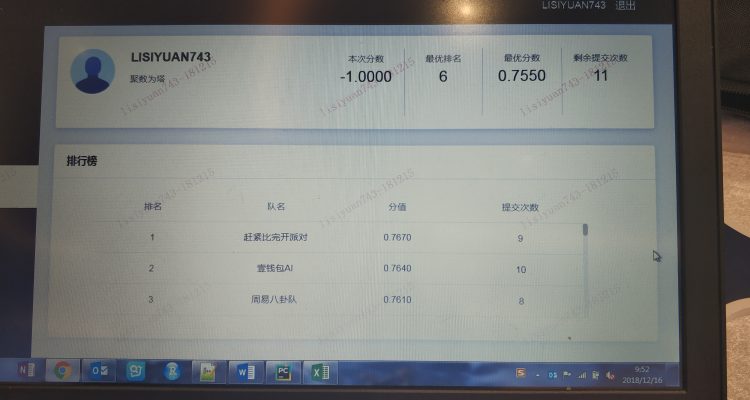
此次比赛最后得到的结果是第6名,由于没有拿到奖金,这个结果我不是很满意,人力上的吃亏有较大的影响。但比赛结束后,前三名的队伍分享了经验,我对他们的方法也表示非常赞赏,认为自己和他们在数据的理解,以及模型知识上确实存在较大的差距。
前三名在比赛的过程中,都花了大量的时间观察数据,最后发现了数据之间的一些规律。针对这些规律进行了特征工程,虽然大家最后选择的模型方法都差不多,但正是由于他们特征工程做得好,因此得到了很好的效果。
而我这边,由于没有时间进行特征工程,直接将数据丢入模型内,造成了比分上的落后。
比赛结尾的时候,集团的首席科学家肖京有个观点令我观点非常认同。
他认为:我们过于强调特征工程的重要性了,对于模型我们反而认为没那么重要。这一点是很不正常的,因为对于真实生成而言,往往是结构化的数据少于非结构化的数据,机器学习不就是为了解决复杂问题么。因此,需要弱化人工的干预,减少人类经验对特征进行修饰干预。但肖博士现场也指出,我们大量做特征工程,是因为现场比赛的时间太少,复杂模型搭建成本较大,而且没有时间来验证模型效果。
这次比赛,让我最大的收获就是体验到了现场比赛的气氛,看到了大家的脑洞大开,感受到了参赛选手对数据分析的热情。
对我而言,热情是最重要的品质。希望自己能继续进步,保持热情,收获更多的知识。
The End
已发布
分类
标签:
您的电子邮箱地址不会被公开。 必填项已用*标注
评论 *
显示名称
电子邮箱地址
网站地址
Δ









发表回复