好的数据可视化,可以使得数据分析的结果更通俗易懂。“词云”就是数据可视化的一种形式。给出一段文本的关键词,根据关键词的出现频率而生成的一幅图像,人们只要扫一眼就能够明白文章主旨。
今天我们就来聊一聊用python生成词云的方法,用较少的篇幅介绍完词云的实现方法.
 简单英文词云
简单英文词云首先,我们提供了一个文本文件,当做素材.点击此处下载文本文件:
直接贴代码,生成简单词云
# -*- coding: utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 打开文本
text = open('../constitution.txt').read()
# 生成对象
wc = WordCloud().generate(text)
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存到文件
wc.to_file('wordcloud.png')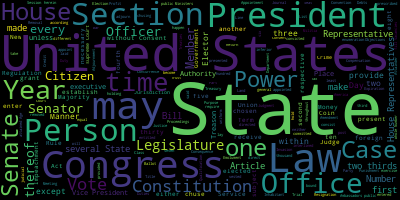 可以很容易看出上面那个文本文件的主题词
可以很容易看出上面那个文本文件的主题词wordcloud整的很方便,不仅能迅速生成词云图,还能自动统计文章中文本的频次.
简单中文词云
前面提供了一种生成英文词云的方法,这里提供一种中文词文的生成方法.这里我们使用的是我国四大名著之一<<西游记>>,点击此处下载文本文件:
# -*- coding: utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 打开文本
text = open('../xyj.txt').read()
# 生成对象
wc = WordCloud(font_path='../Hiragino.ttf', width=800, height=600, mode='RGBA', background_color=None).generate(text)
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存到文件
wc.to_file('wordcloud.png')我们使用的是wordcloud自带的分词方法,这里我们使用了字体Hiragino.ttf,由于本站点不方便上传,读者可以自行下载自己喜欢的字体.
 可以看出来,西游记中出现最多的词是”行者”,”师傅”,”八戒”
可以看出来,西游记中出现最多的词是”行者”,”师傅”,”八戒”我们可以使用jieba进行分词,得到分词结果后,统计词频.再绘制词云图
# -*- coding: utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
# 打开文本
text = open('../xyj.txt').read()
# 中文分词
text = ' '.join(jieba.cut(text))
print(text[:100])
# 生成对象
wc = WordCloud(font_path='../Hiragino.ttf', width=800, height=600, mode='RGBA', background_color=None).generate(text)
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存到文件
wc.to_file('wordcloud.png') 可以看出来,使用jeiba分词得到的词频和wordcloud默认的分词结果相差无几
可以看出来,使用jeiba分词得到的词频和wordcloud默认的分词结果相差无几图形化词云
为了让词云图更加个性化,我们还可以指定词云的形状,这里我们仍然使用<<西游记>>作为素材来绘制词云图.我们使用的背景图是这个.

这里我们使用jieba进行分词
# -*- coding: utf-8 -*-
from wordcloud import WordCloud
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba
# 打开文本
text = open('../xyj.txt').read()
# 中文分词
text = ' '.join(jieba.cut(text))
print(text[:100])
# 生成对象
mask = np.array(Image.open("../sun2.jpg"))
wc = WordCloud(mask=mask, font_path='../Hiragino.ttf', mode='RGBA', background_color=None).generate(text)
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
# 保存到文件
wc.to_file('wordcloud.png')
得到了上面这个词云图,可以看出来轮廓和模板图片是一致的,颜色也是匹配的.上面的图片看起来不明显,将两张图片放到一起对比一下.


总结
- 不仅可以使用jieba或者是其他的分词工具,还可以直接输入文字,以及每个词出现的频率(可以直接理解成在词云图中的比例)来获得词云
- 在选择背景图片的时候,最好是选择背景是白色的,或者使用后期软件将图片的对比度增加,获得纯净的背景.
- 背景图可以使用轮廓鲜明,辨识度较好的图片
到这里为止,已经介绍忘了词云的基本使用方法.个性化的定制,可以对字体,颜色,词云轮廓等方面进行修改.

发表回复